La implementación de una estrategia de optimización de motores de búsqueda generalmente requiere herramientas que pueden ser peligrosas si se manejan incorrectamente. Conocer esas herramientas, cuándo y cómo usarlas, puede marcar la diferencia.
Esta es la 12ª y última publicación de mi serie “Cómo hacer SEO”. Las cuotas anteriores son:
- “Parte 1: ¿Por qué usarlo?”;
- “Parte 2: Comprensión de los motores de búsqueda”;
- “Parte 3: Estrategia y planificación”;
- “Parte 4: Conceptos de investigación de palabras clave”;
- “Parte 5: Análisis de datos de palabras clave”;
- “Parte 6: Optimización de elementos en la página”;
- “Parte 7: Asignación de palabras clave al contenido”;
- “Parte 8: Arquitectura y vinculación interna”;
- “Parte 9: Diagnóstico de problemas de rastreadores”;
- “Parte 10: Rediseños, Migraciones, Cambios de URL”;
- “Parte 11: Mitigación del riesgo”.
El SEO técnico se centra en algunas áreas críticas: rastreo, indexación y definición de tipos de contenido.
Regulación de los rastreadores de motores de búsqueda
El requisito de búsqueda orgánica más fundamental es permitir que los rastreadores de motores de búsqueda (bots) accedan a su sitio. Sin el rastreo, los motores de búsqueda no pueden indexar y clasificar sus páginas.
Las herramientas de rastreo le permiten abrir o cerrar la puerta para buscar bots página por página. Use las herramientas para bloquear bots amigables del contenido que no desea en el índice de Google, como el carrito de compras y las páginas de la cuenta.
El archivo Robots.txt, ubicado en el directorio raíz de su dominio, le dice a los bots qué páginas deben rastrear. Por ejemplo, el archivo robots.txt de Practical Ecommerce se encuentra en Practicalecommerce.com/robots.txt.
El acceso al sitio completo es el predeterminado; no es necesario habilitar el acceso. La emisión de comandos de rechazo impide que los robots de búsqueda de buena reputación accedan a una o más páginas. Los robots molestos, como los raspadores que copian su contenido para volver a publicar en sitios de spam, no obedecerán a los archivos robots.txt. Sin embargo, para fines de SEO, el archivo robots.txt funciona bien.
Consulte mi publicación de abril para obtener más información sobre robots.txt.
Etiqueta noindex de meta robots . Aplicado a páginas individuales, el atributo noindex de la metaetiqueta de robots , generalmente llamado simplemente etiqueta noindex , puede evitar que los bots indexen páginas individuales. Se encuentra en el encabezado del código HTML de su página con sus etiquetas de título y meta descripción.
La metaetiqueta noindex puede ser poderosa pero también peligrosa. Cuando se utiliza en una plantilla de página, la metaetiqueta noindex corta la indexación de cada página de esa plantilla.
Otros atributos, como nofollow , nocache y nosnippet , están disponibles con la metaetiqueta robots para, respectivamente, restringir el flujo de autoridad del enlace, evitar el almacenamiento en caché de la página y solicitar que no se muestre ningún fragmento del contenido de la página en los resultados de búsqueda.
Consulte mi publicación de abril para obtener consejos sobre cómo administrar etiquetas noindex .
Habilitación de la indexación
Las herramientas de indexación guían a los motores de búsqueda hacia el contenido que desea que aparezca en los resultados de búsqueda orgánicos.
Mapa del sitio XML. A diferencia de un mapa de sitio HTML, al que muchos sitios enlazan en el pie de página, los mapas de sitio XML son una lista clara de URL y sus atributos. Los bots utilizan mapas de sitio XML para aumentar la lista de páginas que descubren al rastrear su sitio. Los mapas de sitio XML invitan a los robots a rastrear las páginas, pero no garantizan la indexación.
El año pasado abordé la estructura y las limitaciones de los mapas de sitio XML.
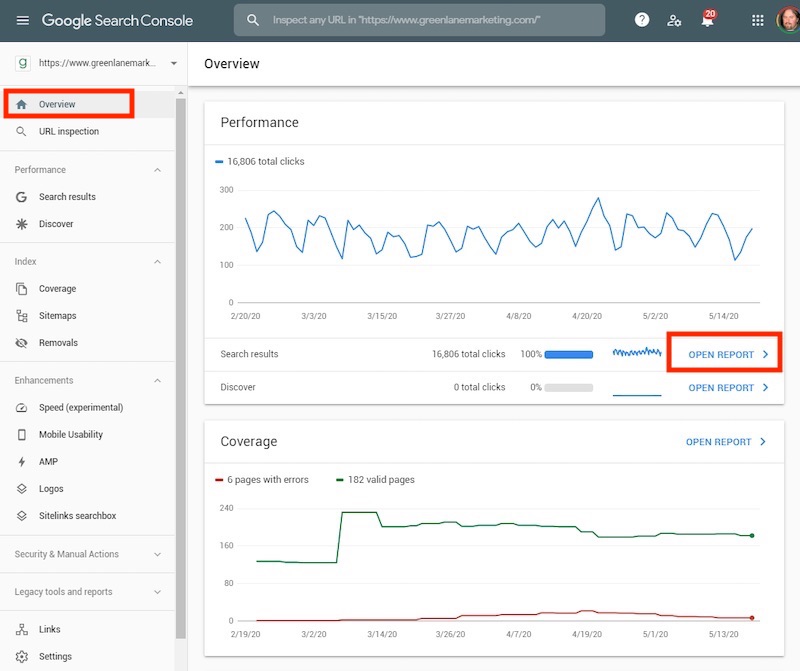
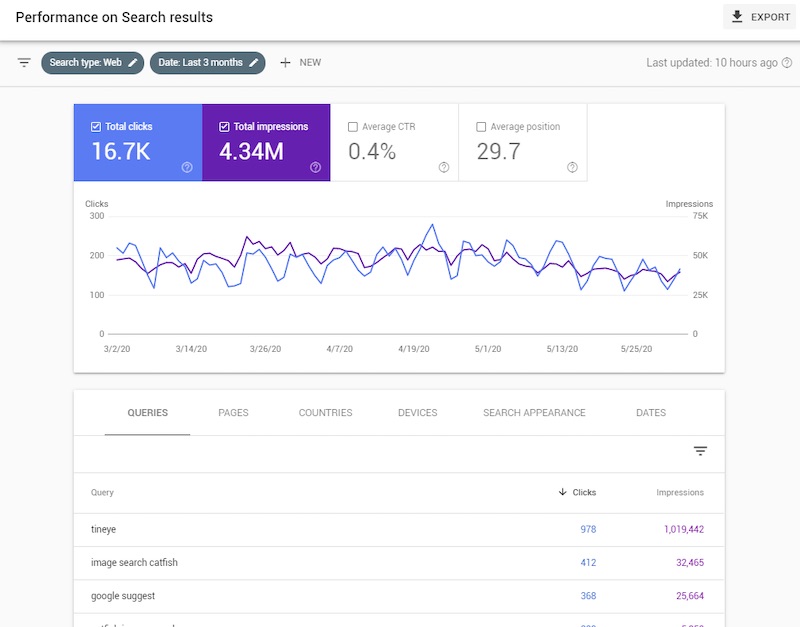
Google Search Console y Bing Webmaster Tools. Una vez que tenga un mapa del sitio XML, envíelo tanto a Google Search Console como a Bing Webmaster Tools. Eso, y hacer referencia a la URL del mapa del sitio XML en su archivo robots.txt, garantiza que los bots puedan encontrarlo.
Sin embargo, el envío del mapa del sitio no es la única razón para registrarse en los conjuntos de herramientas para webmasters de Google y Bing. También sirven como paneles de rendimiento para cada motor de búsqueda. Además, la Consola de búsqueda de Google incluye una herramienta de inspección de URL para solicitar la indexación de cualquier URL en su dominio.
Eliminando URL indexadas
Asegúrese de que desea que el contenido se rastree e indexe antes de que se publique. Es mucho más fácil evitar la indexación que eliminarla después. Sin embargo, si necesita eliminar páginas de un índice de motor de búsqueda, como por ejemplo para contenido duplicado o información de identificación personal, considere estos métodos.
404 archivo no encontrado. La forma más rápida de eliminar una página de un índice de búsqueda es eliminarla de su servidor web para que devuelva un error 404 de archivo no encontrado.
Sin embargo, los errores 404 son callejones sin salida. Toda la autoridad que la página en vivo se había ganado con el tiempo (de otros sitios vinculados a ella) muere. Siempre que sea posible, utilice otro método para desindexar el contenido.
Vea mi publicación sobre errores 404.
Los redireccionamientos 301 son solicitudes de encabezado del servidor web al usuario antes de que se cargue una página, lo que indica que la página solicitada ya no existe. Es poderoso porque también ordena a los motores de búsqueda que transfieran toda la autoridad de la página anterior a la página a la que se redirige, fortaleciendo esa URL receptora. Utilice redireccionamientos 301 siempre que sea posible para eliminar contenido, preservar la autoridad del enlace y mover al usuario a una nueva página.
Vea mi publicación sobre redireccionamientos 301.
Etiquetas canónicas. Otra forma de metadatos que se encuentra en el encabezado del código de una página, la etiqueta canónica le dice a los rastreadores de los motores de búsqueda si la página es la fuente canónica (es decir, autorizada). Las etiquetas canónicas pueden desindexar páginas y agregar autoridad de enlace a la versión canónica.
Las etiquetas canónicas son útiles para administrar páginas duplicadas, algo común en los catálogos de productos de comercio electrónico.
Las etiquetas canónicas son una solicitud, no un comando como las redirecciones 301. Aún así, son efectivos cuando necesitas que humanos accedan a una página, pero no quieres que los motores de búsqueda la indexen.
Vea mi publicación sobre etiquetas canónicas.
Herramienta de eliminación de Google. Otra característica de la Consola de búsqueda de Google, la herramienta Eliminaciones puede eliminar temporalmente páginas del índice de Google. Sin embargo, tenga cuidado, ya que he visto sitios completos eliminados accidentalmente con un solo clic.
La herramienta Eliminaciones es una buena opción cuando necesita eliminar rápidamente información obsoleta o confidencial de los resultados de búsqueda. Sin embargo, si desea que la eliminación sea permanente, deberá eliminar la página de su sitio (para devolver un error 404) o colocar una etiqueta noindex en ella. De lo contrario, Google volverá a rastrear y volver a indexar la página en un plazo de seis meses.
Para obtener más información, consulte la explicación de la “Herramienta de eliminación” de Google.
Definición de contenido
Por último, los datos estructurados pueden definir tipos de contenido para ayudar a los motores de búsqueda a comprenderlos. Los datos estructurados también pueden activar la ubicación de fragmentos enriquecidos y paneles de conocimiento en los resultados de búsqueda orgánicos de Google.
Por lo general, codificados con JSON-LD o el estándar de microdatos, los datos estructurados colocan bits de metadatos en las plantillas de página existentes. El código rodea los elementos de datos existentes, como el precio, las calificaciones y la disponibilidad.
Abordé los datos estructurados para las páginas de productos de comercio electrónico el año pasado.