Los motores de búsqueda deben rastrear e indexar su sitio antes de que pueda clasificarse en la búsqueda orgánica. Por lo tanto, optimizar su contenido no tiene sentido si los motores de búsqueda no pueden acceder a él.
Esta es la novena entrega de mi serie “Cómo hacer SEO”. Las cuotas anteriores son:
- “Parte 1: ¿Por qué usarlo?”;
- “Parte 2: Comprensión de los motores de búsqueda”;
- “Parte 3: Dotación de personal y planificación para SEO”;
- “Parte 4: Conceptos de investigación de palabras clave”,
- “Parte 5: Análisis de datos de palabras clave”
- “Parte 6: Optimización de elementos en la página”;
- “Parte 7: Asignación de palabras clave al contenido”;
- “Parte 8: Arquitectura y vinculación interna”.
En la “Parte 2”, hablé de cómo los motores de búsqueda rastrean e indexan el contenido. Cualquier cosa que limite las páginas rastreables puede acabar con su rendimiento de búsqueda orgánica.
Bloqueo accidental
Es el peor de los casos en la optimización de motores de búsqueda: su empresa ha rediseñado su sitio y, de repente, el rendimiento orgánico se bloquea. Sus análisis web indican que el tráfico de la página de inicio es relativamente estable. Pero el tráfico de la página del producto es menor y sus nuevas páginas de cuadrícula de navegación no se encuentran en ningún lugar de Google.
¿Que pasó? Es probable que tenga un problema de rastreo o indexación.
Los bots han recorrido un largo camino. Los principales motores de búsqueda afirman que sus bots pueden rastrear JavaScript. Eso es cierto hasta cierto punto. Pero la forma en que los desarrolladores codifican cada fragmento de código JavaScript determina si los motores de búsqueda pueden acceder o comprender el contenido.
Su navegador es mucho más indulgente que los bots. Es posible que los bots no puedan rastrear el contenido que se muestra en la pantalla y funciona correctamente en su navegador. Los ejemplos incluyen la incapacidad de los bots para reconocer enlaces internos (dejar secciones enteras huérfanas) o representar correctamente el contenido de la página.
Los bots más avanzados interpretan una página como la ven los humanos en los navegadores actualizados y envían la información al motor de búsqueda para representar los diferentes estados para contenido y enlaces adicionales.
Pero eso se basa en el robot de búsqueda más avanzado (i) que rastrea sus páginas, (ii) identifica y activa elementos como la codificación de enlaces no estándar en la navegación y (iii) evalúa la función y el significado de una página.
El rastreo tradicional se basa en el texto HTML y los enlaces para determinar la relevancia y la autoridad al instante. Pero el rastreo avanzado en JavaScript, por ejemplo, puede llevar semanas, si es que ocurre.
En resumen, invierta tiempo para identificar y resolver los bloqueadores de rastreo en su sitio.
Prueba de rastreo
Desafortunadamente, las herramientas disponibles públicamente como DeepCrawl y SEO Spider de Screaming Frog no pueden replicar perfectamente los robots de búsqueda modernos. Las herramientas pueden mostrar resultados negativos cuando un robot de búsqueda puede acceder al contenido.

SEO Spider de Screaming Frog es una herramienta útil para identificar posibles errores de rastreo, al igual que DeepCrawl. Sin embargo, tampoco es infalible replicar perfectamente los robots de búsqueda.
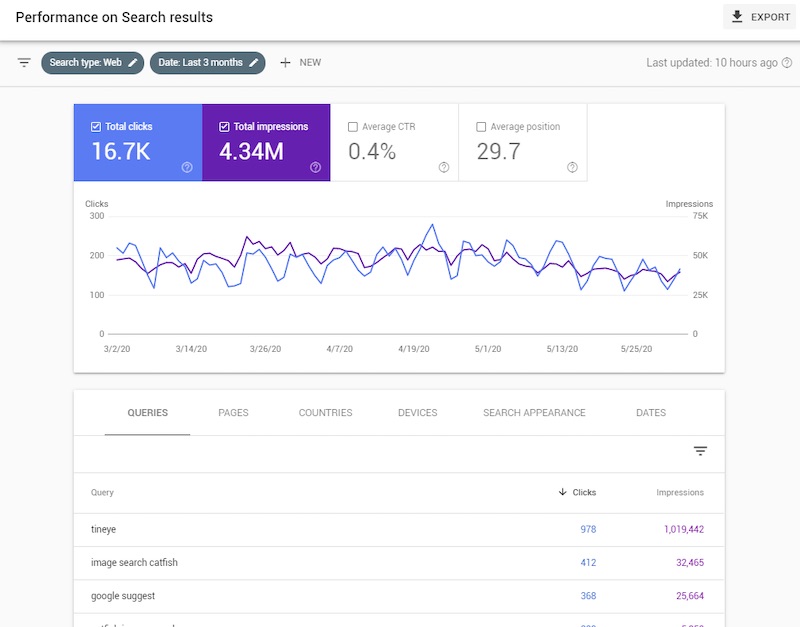
El primer paso para probar si los robots de búsqueda pueden rastrear todo su sitio es verificar el índice de Google. En la barra de búsqueda de Google, escriba “sitio:” antes de cualquier URL que desee verificar, como:
site:www.mysite.com/this page/
Las consultas del sitio devuelven una lista de páginas que Google ha indexado que comienzan con la cadena de URL que ingresó. Si las páginas que faltan en sus análisis también faltan en el índice de Google, podría tener un bloqueo de rastreo. Sin embargo, si las páginas están indexadas pero no generan tráfico orgánico, es probable que tenga un problema de relevancia o autoridad de enlace.
También puede verificar la indexación en Google Search Console con la herramienta de “inspección de URL”, pero solo una página a la vez.
Si la consulta del sitio no encuentra páginas, intente rastrear su sitio con Screaming Frog o DeepCrawl. Deje que el rastreador se ejecute en su sitio y busque áreas faltantes de un determinado tipo: cuadrículas de exploración, páginas de detalles de productos, artículos.
Si no ve agujeros en el rastreo, es probable que su sitio sea rastreable. Los robots de búsqueda, nuevamente, son más capaces que las herramientas de rastreo. Si una herramienta puede atravesar el contenido de un sitio, también puede buscar bots. Y los problemas identificados en una herramienta de rastreo podrían ser falsos negativos.
Además, use herramientas de rastreo en entornos de preproducción para identificar problemas de rastreo antes del lanzamiento, o al menos proporcionar una idea de lo que enfrentará cuando se active.
Consulte “Parte 10: Rediseños, migraciones, cambios de URL”.